12月6日-12月10日,全球自然语言处理领域的顶级会议EMNLP2023在新加坡召开,公司研究生一年级同学王海及导师任函副研究员撰写的长文论文《Time-Aware Language Modeling for Historical Text Dating》被接收并发表。
EMNLP是计算机语言学和自然语言处理领域的顶级国际会议之一,在Google Scholar计算语言学刊物指标中排名第二,是中国计算机学会(CCF)推荐的 B 类国际学术会议。
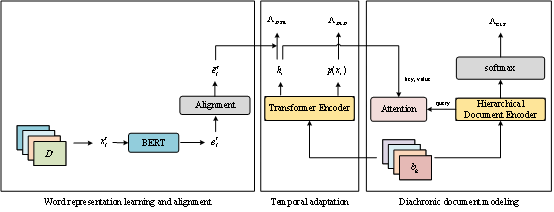
论文概述:自动文本定年(Automatic text dating)是文本分析任务中的一个具有挑战性的问题,旨在预测输入文本所属的年代。现有工作主要通过语言模型来学习单词表征,然而大多数方法都忽略了单词的历时演化特征,这可能会影响文本建模的效果。针对这一现象,本文提出了一种时间感知语言模型TALM,该模型学习同一词汇在不同时域下的表征,用于对不同时域的文本进行建模。具体来说,论文首先学习各词汇在不同时域的表示,然后将不同时域的词汇表示映射到同一语义空间。在此基础上,论文提出了一种时间自适应方法,用于学习与所属文档具有一致时域的词汇表示。随后,论文设计了一种桥接机制,将学到的词汇表示融入层次文档表示模型中,用于对文档进行年代预测。在中文和英文两种数据集上进行了实验,结果表明,在文本建模过程中融合词义演化特征有助于更好地刻画文本的时间信息。
模型图
初稿:王海
复审:吴笛
终审:王连喜





